推荐人: 华中科技大学管理学院 尤思余
原文信息: Alatas V, Banerjee A, Hanna R, Benjamin A. Olken, Purnamasari R, Wai-Poi M. Self-targeting: Evidence from a field experiment in Indonesia[J]. Journal of Political Economy, 2016, 124(2): 371-427.
一、引言
在设计有针对性的社会援助计划时,如何将穷人和富人分离开是长期存在的问题。有一类解决办法是设置申请条件,使得富人的申请成本高于穷人(Nichols, Smolensky, and Tideman 1971;Nichols and Zeckhauser 1982;Ravallion 1991;Besley and Coate 1992)。这种自我选择机制(self-selection mechanisms)在社会福利计划中应用十分广泛,例如如今印度的全国农村就业保障法案对接受援助的对象有手工劳动要求,补贴食品计划常常提供较低质量的食品,这些设计使得只有特定类别的人群申请福利。但自我选择机制往往可能是无效率的,因为它使得穷人被迫承担大量的申请成本。
那么,是否可以用很小的成本实现较大的自我选择效应呢?本文基于印度尼西亚有条件的现金转移计划PKH开展了一项随机试验:将400个村庄随机等分为两组,一组为自我定位组(self-targeting treatment),感兴趣的村民需要到申请中心提交资助申请并接受资产审查,这会花费申请者部分时间和金钱成本。一组为自动识别组(automatic screening treatment),统计中心和当地政府合作,列举潜在受益者名单并对每户家庭进行资产访谈,自动登记通过筛选程序的家庭。通过比较两组方法的瞄准度,作者发现,自我定位组(self-targeting treatment)要求申请者付出一定的申请成本,同时通过一个较好但不完美的筛选程序剔除不合适的申请者,这种设计使得富人可以准确地预测自己通过筛选的机会很小而选择不去申请,从而提高了援助计划的瞄准度。作者还发现边际增加申请成本并不会进一步提高瞄准度。
二、制度及理论模型
印度尼西亚PKH计划针对人均消费低于贫困线80%并满足人口要求的家庭。计划受益人每年收到现金资助USD$67–$250,共发放6年。2013年,该政策惠及240万个家庭。PKH计划使用代理平均(a proxy means test,以下简称PMT)的方法识别贫困人群,对申请者进行资格筛选。政府利用调查数据获得地区层面的家庭人均消费计算公式,由此计算申请者的PMT分数,若该分数低于每个地区的贫困线,则申请者获得资助资格。

本文作者在六个地区随机选择400个村庄(villages),并在每个村庄随机选择一个湾组(hamlets)进行调查。本文获取了三轮家庭层面的调查数据(如表2),主要包括家庭消费水平、成员基本情况、申请过程以及满意度等信息。
作者通过构建一个简单的两阶段申请决策模型探讨了影响自我选择效应的因素。作者将家庭分为两类,敏锐(Sophisticated households)和迟钝(Unsophisticated households),前者知道政府通过可观测收入判断申请者是否有资格获得资助,后者则对此一无所知。那么

为敏锐家庭申请的概率;
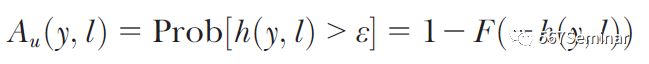
为迟钝家庭申请的概率。
其中,yo代表可观测收入,y代表总收入,l代表到申请中心的距离,ε代表效用冲击,g(yo,y,l)和h(y,l)分别代表两类家庭申请的净收益(net gains)。
作者发现,对于Sophisticated households,不可观测收入(yu)仅仅通过申请成本影响家庭的申请决策,而对于Unsophisticated households,不可观测收入(yu)同时还影响着他们对于自身获得资助资格的预期。正是后者的存在使得基于自我选择机制(self-selection mechanisms)的自我定位组(self-targeting treatment)较之自动识别组(automatic screening treatment)有更高的瞄准度。
三、实证结果
本文主要通过4个阶段展示实证结果:谁选择申请PKH计划;自我定位组和自动识别组的优劣比较;申请成本的边际变动是否可以提高自我定位方法的瞄准度(targeting performance);利用GMM估计模型参数并进行机制检验。最后作者比较两种方法的贫困减少度。
(一)谁选择申请PKH?
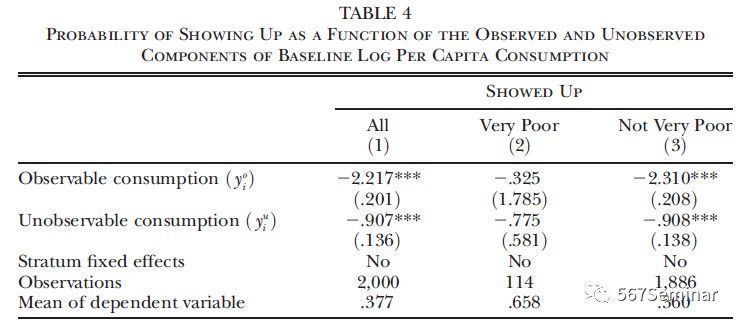
作者通过图形和回归表格(如表4)都说明穷人比富人更有可能去申请PKH计划。一方面从可观测收入考虑,拥有更多资产的家庭通过PMT的可能性更小,从而更不可能去申请资助,这将会减少政府的行政成本;另一方面从不可观测收入考虑,拥有更高不可观测消费水平的家庭申请的可能性更小,因为他们要考虑时间机会成本或者他们不知道PMT分数的构成。基于不可观测收入的选择使得自我定位法较之其他方法更能聚焦于穷人。
(二)比较自我选择和自动识别
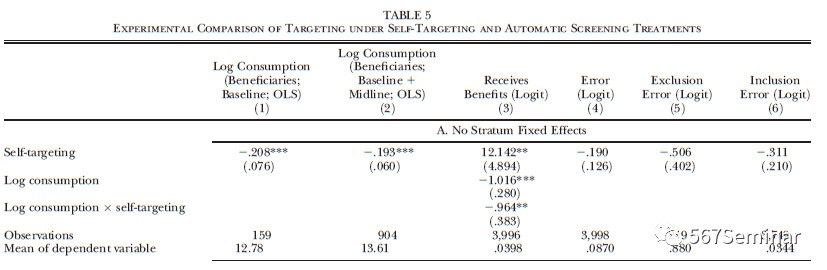
首先,作者将自我定位法和政府常用的自动识别法进行比较。发现前者比后者的受益者更穷,前者既增加了穷人获得资助的可能性,又减少了富人获得资助的可能性。作者还比较了两者的错误率,结果如表5所示。

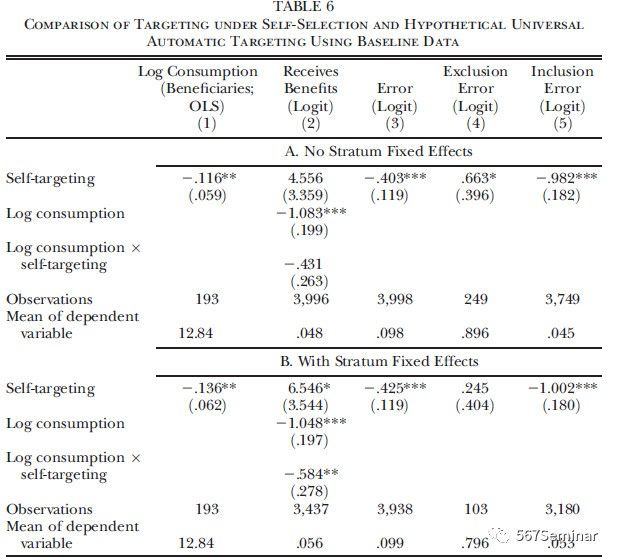
其次,作者考虑到政府常用的自动识别法会事先对潜在受益者家庭进行筛选,并非所有家庭进入到资产审查阶段,这可能会导致部分符合资格的家庭被遗漏。因此,作者将自我定位法与未经过事前筛选的自动识别法(政府对每个家庭都进行PMT采访)进行比较。结果如表6所示,与表5结论类似。
(三)申请成本变化的边际效应 本文作者在此部分通过改变到申请中心的距离来改变申请成本,以此探讨成本的边际变动是否会影响自我定位法的瞄准度。如表7所示,增加距离会减少申请数量但并不会影响申请者的分布。
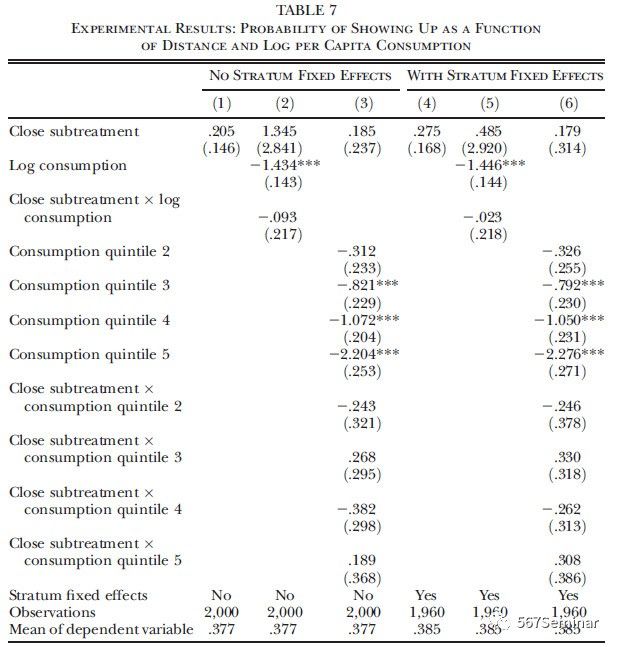
(四)利用模型探讨理论机制
作者目前通过实证得出结果:给家庭申请援助计划设置一定的申请成本会显著提高计划的瞄准度,使之更聚焦于穷人,但边际增加申请成本并不会进一步提高计划的精准度。作者通过调查数据估计出模型的参数(如表8所示),并用它探讨推动本文实证结果的理论机制。
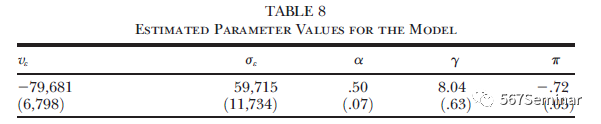
作者利用估计的参数模拟不同假设条件下的申请率,重复表7的Logit回归,同样发现距离变化并不会显著影响计划的瞄准度。
该结果第一种可能的解释是,效用冲击ε抑制了成本效应。通过不断减少冲击ε的标准差,边际成本效应不断增加,如表9列3、列4。
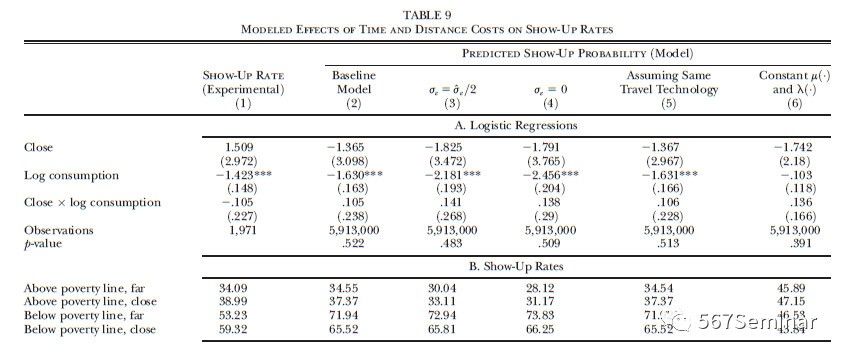

第二种解释可能是穷人和富人有不同的交通方式,使得富人的边际交通成本低于穷人。在表9第5列,作者假设所有家庭的成本是一样的,发现结果和前面实证结果一致,交通工具并不能解释成本边际变动不会影响自我定位法瞄准度的原因。
第三种解释是家庭基于可观测收入和总收入预期其获得资助的可能性是向下倾斜的。在表9第6列,作者假设所有家庭获得资助的可能性是常数,对数人均消费的系数从-1.42(列1)和-1.63(列2)落到-0.10(列6)并且不再显著,说明几乎所有的选择效应都是源于这样一个事实:贫困和富有的申请者对于其获得资助的可能性有着不同的预期。家庭如果预期自己不会获得资助,那么即使很小的申请成本也会有很大的选择效应,因为这些获得资助可能性很低的家庭将不会申请资助,边际增加申请成本也不会显著提高选择效应。
第四种解释是敏锐家庭和迟钝家庭的不同比例会影响结果。增加敏锐家庭的百分比,援助计划受益者的平均消费也会有所增加。这说明,家庭不能准确知道资格计算公式是相当重要的。
本文最后比较自我定位法和自动识别法的贫困差距(poverty gap),发现前者的减少高于后者,增加距离或等待时间都不会进一步提高瞄准度。
四、结论
利用印度尼西亚PKH计划在400个村庄进行田野实验,作者发现对社会援助计划设置一定的申请成本可以显著提高该计划的贫困瞄准度,这是由于穷人比富人更有可能自我选择(self-select)去申请资助,后者会预期其成功获得资助的可能性极低而选择不去申请。
相比于目前政府广泛使用的自动识别法,这类行政成本可以成为提高援助计划贫困人群瞄准度的有力工具,政府可以考虑将其作为一种筛选工具。即使自我定位法优于自动识别法,仍然有很多穷人没有申请资助。如何设计筛选机制来提高穷人的申请率依旧是未来需要探讨的话题。